啰嗦
网页版微博是纯正的HTML,而且调用的微博自家的API来获取图片。
网址:https://m.weibo.cn/api/container/getIndex?type=uid&value= + "id" 即为微博api,里面包含个人信息与微博文案跟照片

代码采用Python3
# -*- coding: utf-8 -*-
import urllib.request
import json
import requests
import os
path = 'D:\\Users\\orange\\Desktop\\weibo\\' # 图片保存路径
id = '6388193945'
proxy_addr = "122.241.72.191:808"
pic_num = 0
weibo_name = "blog.qqccy.cn"
def use_proxy(url, proxy_addr):
req = urllib.request.Request(url)
req.add_header("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 "
"Safari/537.36 SE 2.X MetaSr 1.0")
proxy = urllib.request.ProxyHandler({'http': proxy_addr})
opener = urllib.request.build_opener(proxy, urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data = urllib.request.urlopen(req).read().decode('utf-8', 'ignore')
return data
def get_containerid(url):
global containerid
data = use_proxy(url, proxy_addr)
content = json.loads(data).get('data')
for data in content.get('tabsInfo').get('tabs'):
if data.get('tab_type') == 'weibo':
containerid = data.get('containerid')
return containerid
def get_userInfo(id):
url = 'https://m.weibo.cn/api/container/getIndex?type=uid&value=' + id
data = use_proxy(url, proxy_addr)
content = json.loads(data).get('data')
profile_image_url = content.get('userInfo').get('profile_image_url')
description = content.get('userInfo').get('description')
profile_url = content.get('userInfo').get('profile_url')
verified = content.get('userInfo').get('verified')
guanzhu = content.get('userInfo').get('follow_count')
name = content.get('userInfo').get('screen_name')
fensi = content.get('userInfo').get('followers_count')
gender = content.get('userInfo').get('gender')
urank = content.get('userInfo').get('urank')
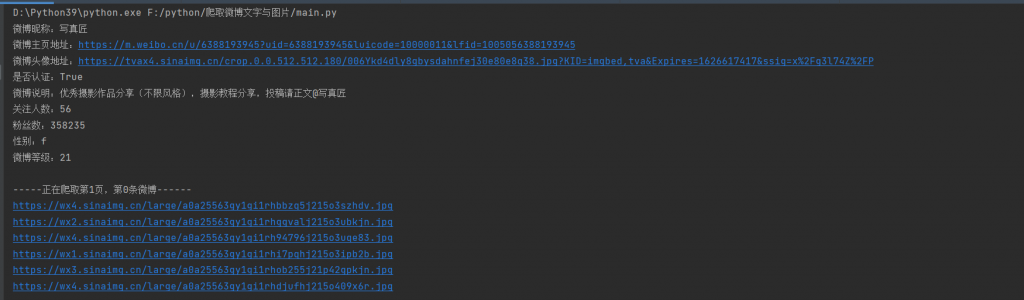
print("微博昵称:" + name + "\n" + "微博主页地址:" + profile_url + "\n" + "微博头像地址:" + profile_image_url + "\n" + "是否认证:" + str(
verified) + "\n" + "微博说明:" + description + "\n" + "关注人数:" + str(guanzhu) + "\n" + "粉丝数:" + str(
fensi) + "\n" + "性别:" + gender + "\n" + "微博等级:" + str(urank) + "\n")
def get_weibo(id, file):
global pic_num
i = 1
while True:
url = 'https://m.weibo.cn/api/container/getIndex?type=uid&value=' + id
weibo_url = 'https://m.weibo.cn/api/container/getIndex?type=uid&value=' + id + '&containerid=' + get_containerid(
url) + '&page=' + str(i)
try:
data = use_proxy(weibo_url, proxy_addr)
content = json.loads(data).get('data')
cards = content.get('cards')
if len(cards) > 0:
for j in range(len(cards)):
print("-----正在爬取第" + str(i) + "页,第" + str(j) + "条微博------")
card_type = cards[j].get('card_type')
if card_type == 9:
mblog = cards[j].get('mblog')
attitudes_count = mblog.get('attitudes_count')
comments_count = mblog.get('comments_count')
created_at = mblog.get('created_at')
reposts_count = mblog.get('reposts_count')
scheme = cards[j].get('scheme')
text = mblog.get('text')
if mblog.get('pics') is not None:
# print(mblog.get('original_pic'))
# print(mblog.get('pics'))
pic_archive = mblog.get('pics')
for _ in range(len(pic_archive)):
pic_num += 1
print(pic_archive[_]['large']['url'])
imgurl = pic_archive[_]['large']['url']
img = requests.get(imgurl)
f = open(path + weibo_name + '\\' + str(pic_num) + str(imgurl[-4:]),
'ab') # 存储图片,多媒体文件需要参数b(二进制文件)
f.write(img.content) # 多媒体存储content
f.close()
with open(file, 'a', encoding='utf-8') as fh:
fh.write("----第" + str(i) + "页,第" + str(j) + "条微博----" + "\n")
fh.write("微博地址:" + str(scheme) + "\n" + "发布时间:" + str(
created_at) + "\n" + "微博内容:" + text + "\n" + "点赞数:" + str(
attitudes_count) + "\n" + "评论数:" + str(comments_count) + "\n" + "转发数:" + str(
reposts_count) + "\n")
i += 1
else:
break
except Exception as e:
print(e)
pass
if __name__ == "__main__":
if os.path.isdir(path + weibo_name):
pass
else:
os.mkdir(path + weibo_name)
file = path + weibo_name + '\\' + weibo_name + ".txt"
get_userInfo(id)
get_weibo(id, file)
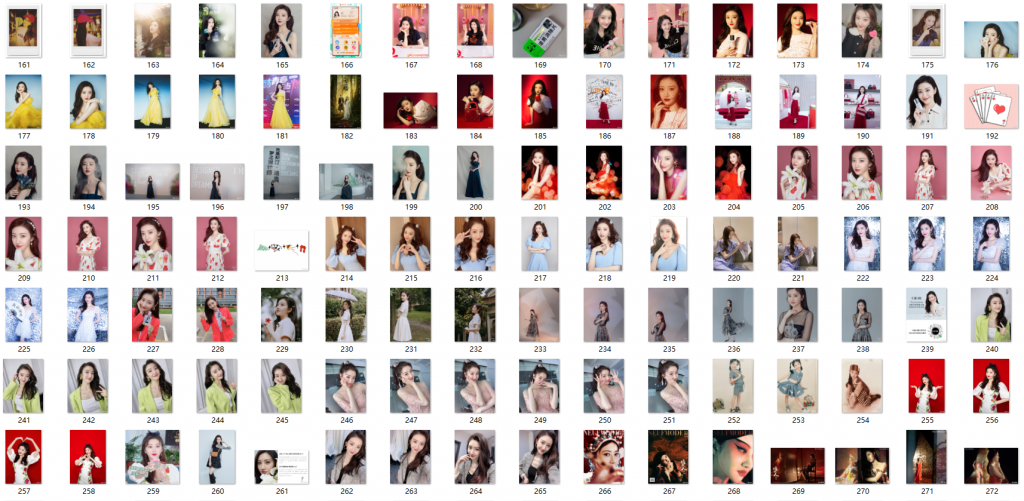
最终的效果图(爬取的微博txt文件):